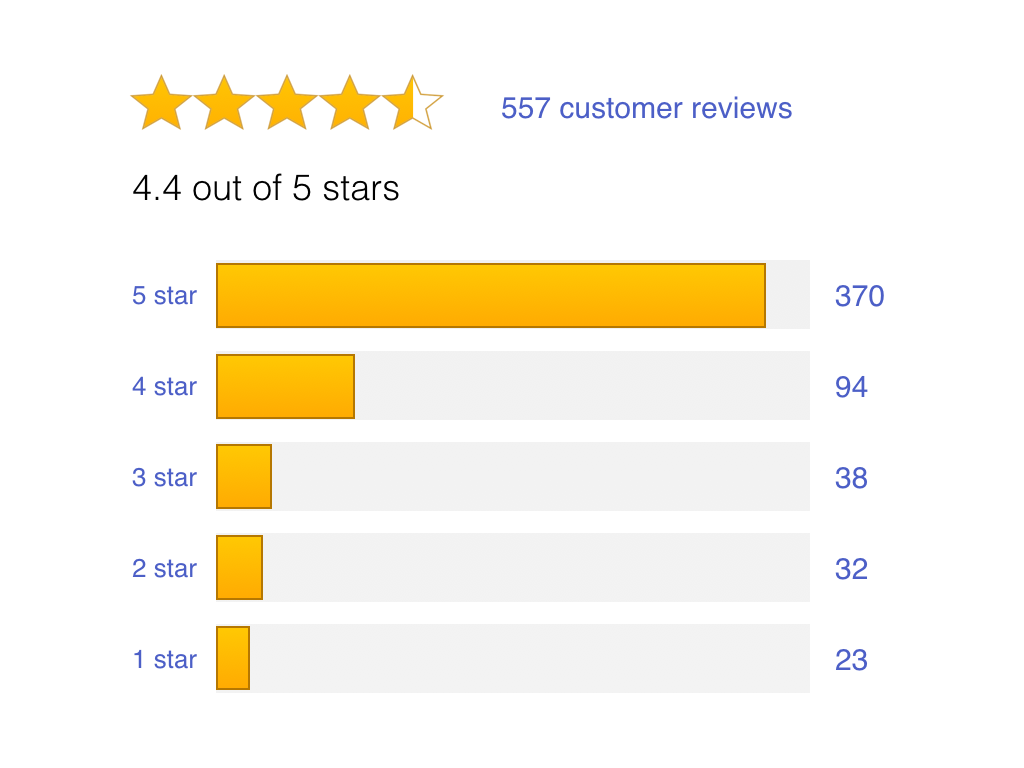
The five-star review system you find on most websites today is inherently flawed if you want information about how good something actually is. Famously, on websites like Amazon, there is a ‘J-shaped’ distribution of review scores. That is, there is a small mass of 1-star reviews; relatively few 2-star, 3-star, and 4-star reviews; and a huge mass of 5-star reviews. This, on it’s own, means that most reviews are somewhat useless. But, when you remember that some of these reviews might be ‘bought’ or faked in some way, it gives you even less of an indication about a product’s value.
The Problem
The problem appears to be due to a disconnect between what people need to do in theory, and what people actually do. A product which is average, relative to its direct substitutes, should receive a score around the middle of the scale. Quality is likely to be somewhat normally distributed. In other words, in a five-star system, most products probably should be rated 3-stars. There will be some products that are slightly better or worse than this average. They will receive 2-stars or 4-stars. 1-star and 5-star reviews should be rare, and reserved for the best and worst products in a category.
Talking with my cousin about this (who has far better industry knowledge than I do), what people seem to actually do is to rate things relative to expectations. This makes sense. Psychology and behavioural economics research has highlighted the fact that people focus more on relative comparisons than absolute ones. It’s pretty difficult to come up with an absolute evaluation when you have a limited sample to work with. A tech magazine may be able to rate TVs out of 10 if they have access to 20 or 30 different models side-by-side. Most people, however, don’t have that luxury.
What ends up happening, then, is that people give 5-stars to anything that ticks off all the mental requirements in an individual’s mind. People then remove stars based on how far expectations have fallen short. More sophisticated people might go for middling scores in that case, but the J-shape that I mentioned earlier suggests that most people just go down to 1-star when expectations have not been met.
Okay, so given people understand this is how the rating system is likely to work, then there’s no need to change it, right?
No. When the metric has an ambiguous interpretation, you get things going wrong when you try to summarise and compare information. If people are rating products in the manner I suggested, what does the mean score mean? A rating scale gives you an objective number. If a smartphone got 4.6 stars, it is supposed to mean that it is a good product. But what if it actually means ‘most people were satisfied with it’? That doesn’t really tell you anything about that phone in relation to other phones you can potentially buy.
In other words, the problem here is that the score is designed to make products easily comparable. Yet, it seems like the way people are scoring makes it impossible to compare numbers in the way you’re supposed to be able to.
A Better System
Expectations appear to be crucial. There is no need for an overall numeric score if people can only consider one product at a time to rate, because they are not rating against anything else. When people want to purchase, they want to know whether a product is ‘good’. But, really, what they mean by this is ‘a product that is good enough to meet my requirements’.
Why not ask people just this? Something like:
- What were you looking for when you bought this product? What were your requirements for it?
- How well did the product match your requirements?
Q1 would be somewhat more free-form. Q2 would be rated on some form of Likert scale. Importantly, the scale should be verbally scored, so that people know what the options mean. For example, one possible list of options could be:
- Perfectly matched all my requirements
- Matched most of my requirements
- Matched some of my requirements
- Didn’t meet my requirements at all
This way, an individual is evaluating a product relative to their internal expectations, and not on the false perception of some objective expectation which they don’t really understand (because they lack the information to make such a judgement).
Reviews should help a consumer to make a purchasing decision. Hence, individuals should be able to filter reviews by expectation keywords. For example, if I were to be in the market for a pair of headphones, I might be looking for accurate sound reproduction and a balanced, neutral sound signature. Other users may judge headphones on quantity of bass. By using keywords like ‘neutral’, ‘balanced’, ‘accurate’, I should be able to bring up only those reviews where the reviewer was also looking for these things. Then, by looking at their answers to Q2, I’d have a pretty good idea of whether the product was what I was looking for.
Of course, this is an early idea and can be improved upon. Perhaps one or two more Likert-based questions could be added to establish, for example, things like reliability. Still, I believe this would be miles better than the 5-point system that most websites seem to be employing right now.
Alternative reasons why you have a skewed distribution of product reviews:
1. Natural selection. Poorly selling products stop selling and you’re left with the good ones hence skewed reviews.
2. Vast majority of products are cheap and simple, with a basic function. Having a 5 star rating system for a battery is pointless, it’s a binary assessment. It either works or doesnt. This could explain the average skew.
Problems with your idea:
1. Anything that takes that long will be filled out by less people. Less reviews is less information and less utility as a review system.
2. Your review system doesn’t give the buyer an opportunity to comment on things other than the product. Delivery price, speed, quality of packaging, customer service etc may also play into an overall rating. This is important as product as a whole.
I would, in general, reject the natural selection idea. Rather, it’s more likely that people only post reviews when they have something very positive or very negative to say.
Agree with the basic function explanation. I think though that that is more grounds for an expectation based review e.g. Expectation = functional battery that doesn’t explode. Meets expectation = yes/no.
Length: In order to leave a review on Amazon, for example, you need to come up with a star rating and write something. That’s a scale-based rating and some text entry. With the two item version I’ve proposed, that’s still the same. It won’t take longer. If people want to skip the text entry and leave an expectation score on a Likert scale, this is no more effort than providing a star rating.
Other things: A product rating is separate from a seller rating, and in this respect I am focusing only on the former. A pair of headphones receiving 1 star ratings because the seller doesn’t send them out on time is not a fair reflection of the product. On the other hand, if the original packaging a product is supplied in is insufficient, then this is something that can contribute to a downward revision of outcome relative to expectation.
Neel, thanks for the article. I find this topic really interesting, and as someone who is annoyed by the uselessness of the 5-star rating I fully support your efforts towards designing a more useful rating system. Another potential upside of the system you are suggesting might be an integration with a recommender system that could give you better suggestions based on keywords from the reviews of products you bought or viewed previously. Improved recommender system might lead to more purchases.
Good point. With expectation keywords, you could be shown a list of ‘best-matching’ products based on the proportion of reviewers that share your expectations and found that they were met.